Longhorn Example v1.1.0 841,894841,894 5.0 (1 reviews)
Description
This dashboard monitors Longhorn storage health and capacity across volumes, nodes, and disks. It highlights key metrics such as longhorn_volume_capacity_bytes, longhorn_volume_state, and longhorn_node_storage_usage_bytes to track volume capacity vs. actual usage, volume robustness/state, and per-node storage consumption, respectively. Core features include consolidated overviews for volumes, nodes, and disks, with counts for states like healthy/degraded/faulted and summaries of capacity versus utilization to identify storage bottlenecks and failed components.
Screenshots
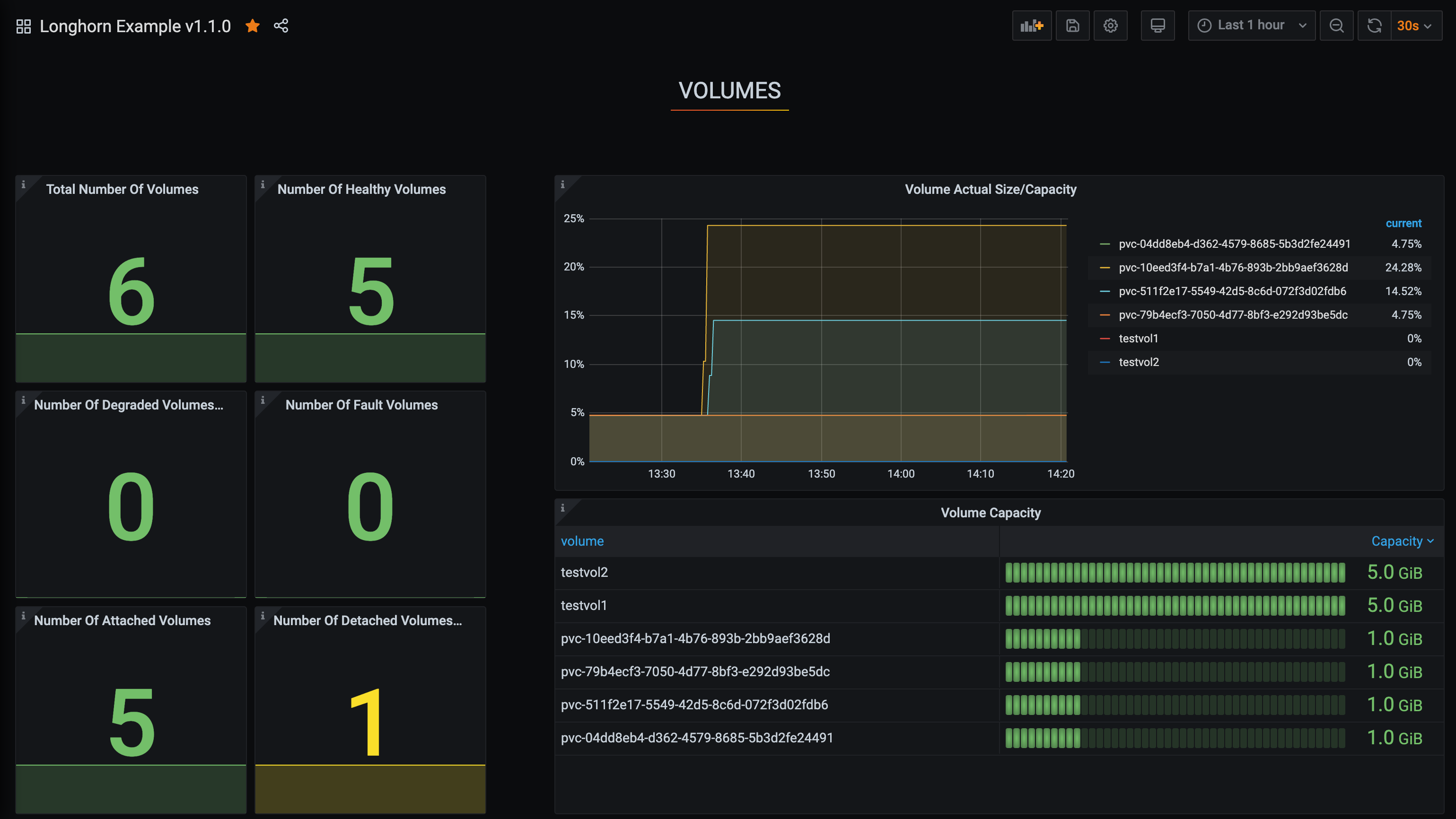
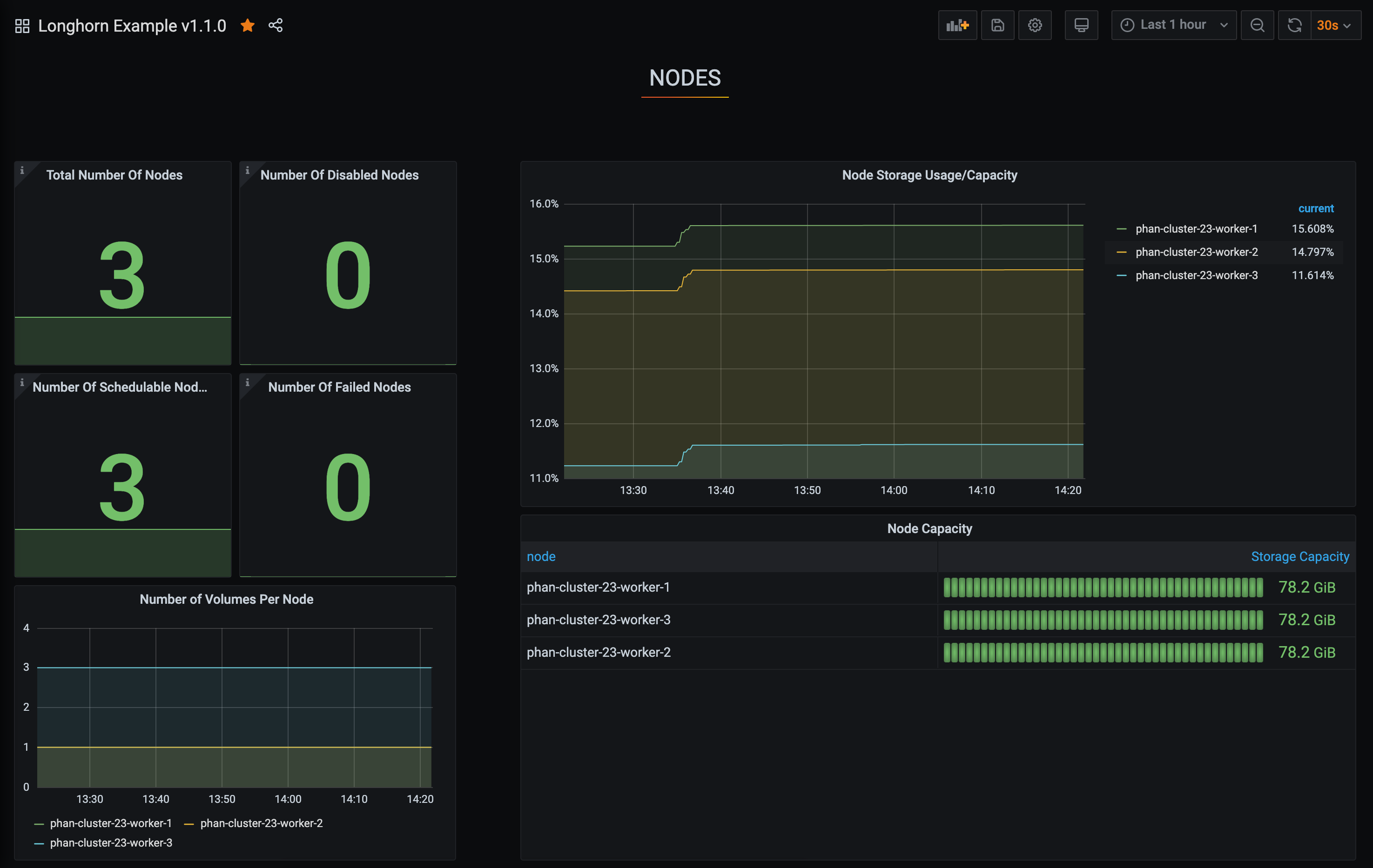
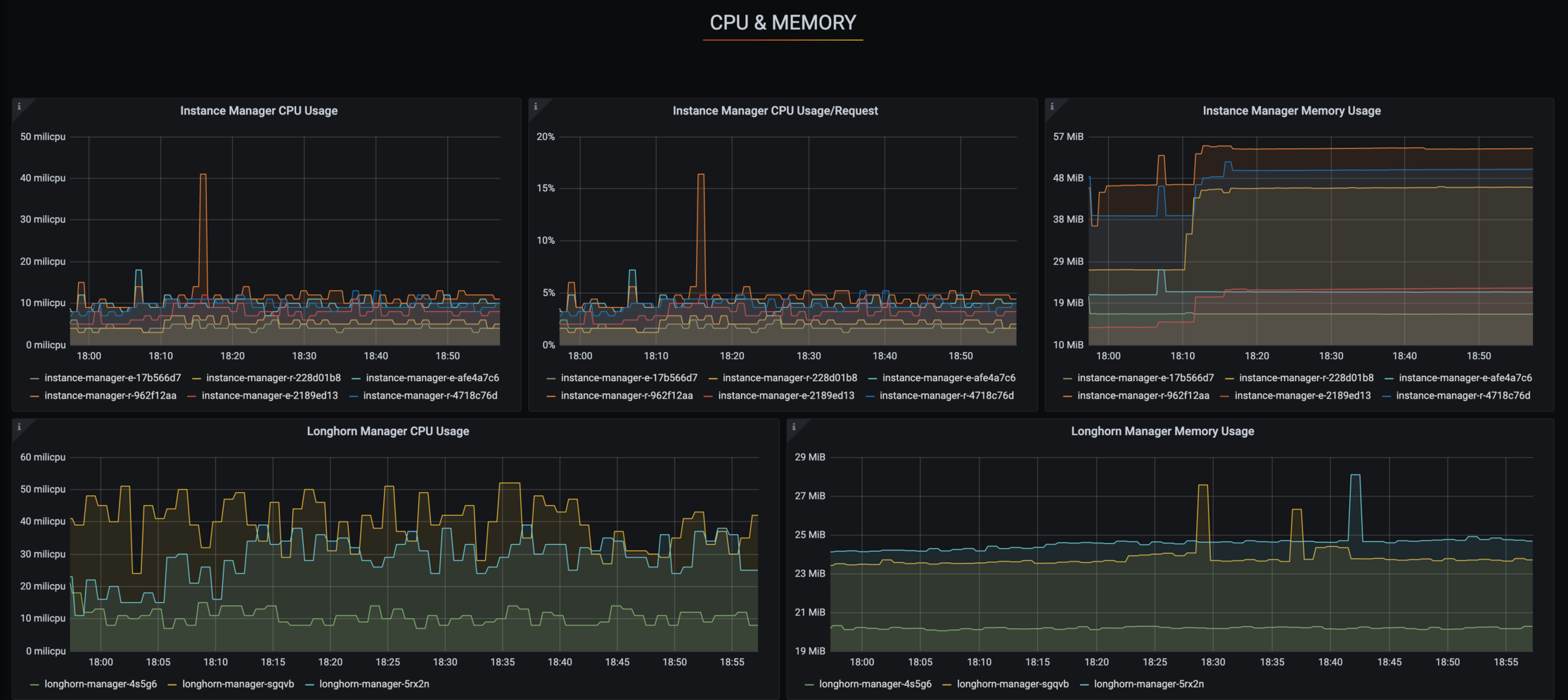
Used Metrics 1919
longhorn_disk_capacity_bytes
longhorn_disk_usage_bytes
longhorn_instance_manager_cpu_requests_millicpu
longhorn_instance_manager_cpu_usage_millicpu
longhorn_instance_manager_memory_usage_bytes
longhorn_manager_cpu_usage_millicpu
longhorn_manager_memory_usage_bytes
longhorn_node_count_total
longhorn_node_cpu_capacity_millicpu
longhorn_node_cpu_usage_millicpu
longhorn_node_memory_capacity_bytes
longhorn_node_memory_usage_bytes
longhorn_node_status
longhorn_node_storage_capacity_bytes
longhorn_node_storage_usage_bytes
longhorn_volume_actual_size_bytes
longhorn_volume_capacity_bytes
longhorn_volume_robustness
longhorn_volume_state