Kubernetes Cluster (Prometheus) 21,581,20521,581,205 3.7 (3 reviews)
Description
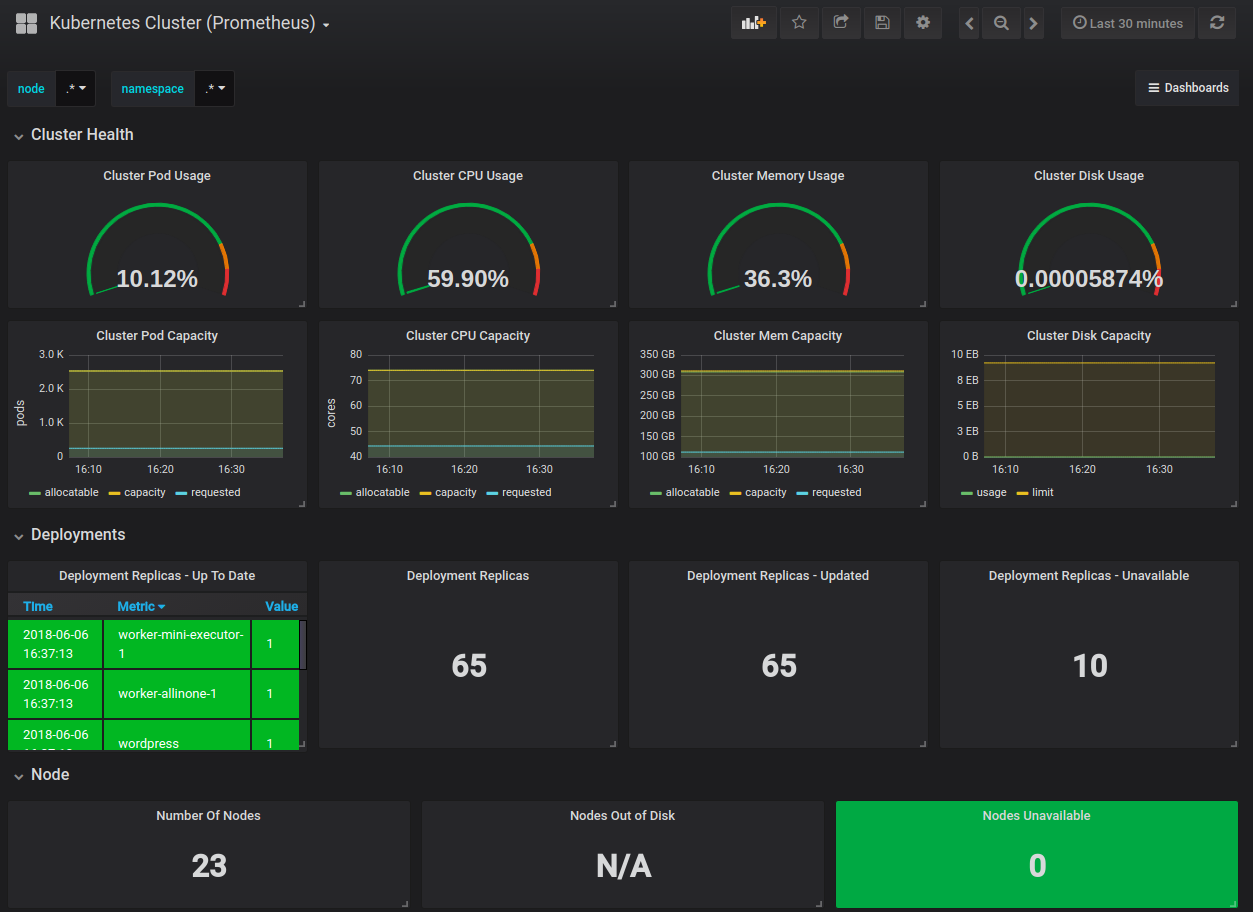
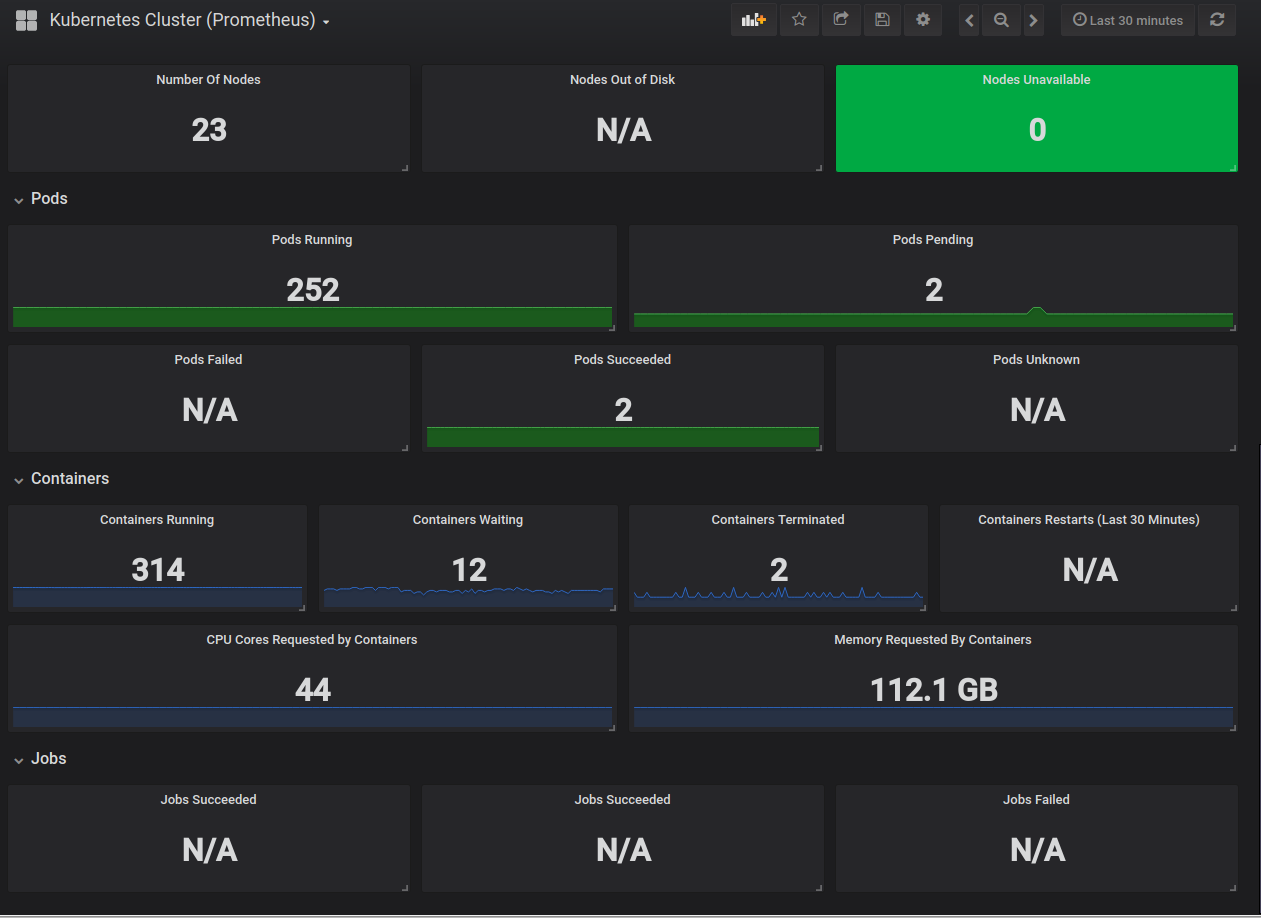
This dashboard provides a comprehensive view of a Kubernetes cluster’s health and capacity by aggregating Prometheus metrics such as pod, node, and resource usage. It highlights core capacity metrics like kube_node_status_allocatable_cpu_cores and kube_node_status_allocatable_memory_bytes alongside pod-level activity (e.g., kube_pod_info, pod counts by status) to track scheduling feasibility and resource pressure across nodes, pods, and deployments.
Screenshots
Used Metrics 2525
kube_deployment_status_replicas
kube_deployment_status_replicas_unavailable
kube_deployment_status_replicas_updated
kube_job_status_active
kube_job_status_failed
kube_job_status_succeeded
kube_node_info
kube_node_spec_unschedulable
kube_node_status_allocatable_cpu_cores
kube_node_status_allocatable_memory_bytes
kube_node_status_allocatable_pods
kube_node_status_capacity_cpu_cores
kube_node_status_capacity_memory_bytes
kube_node_status_capacity_pods
kube_node_status_condition
kube_pod_container_resource_requests_cpu_cores
kube_pod_container_resource_requests_memory_bytes
kube_pod_container_status_restarts
kube_pod_container_status_running
kube_pod_container_status_terminated
kube_pod_container_status_waiting
kube_pod_info
kube_pod_status_phase
node_filesystem_free
node_filesystem_size