K8S - ETCD Cluster Health 1,7901,790
5/29/2020
5/29/2020
1
>=7.0.1
PrometheusPrometheusCloudWatch
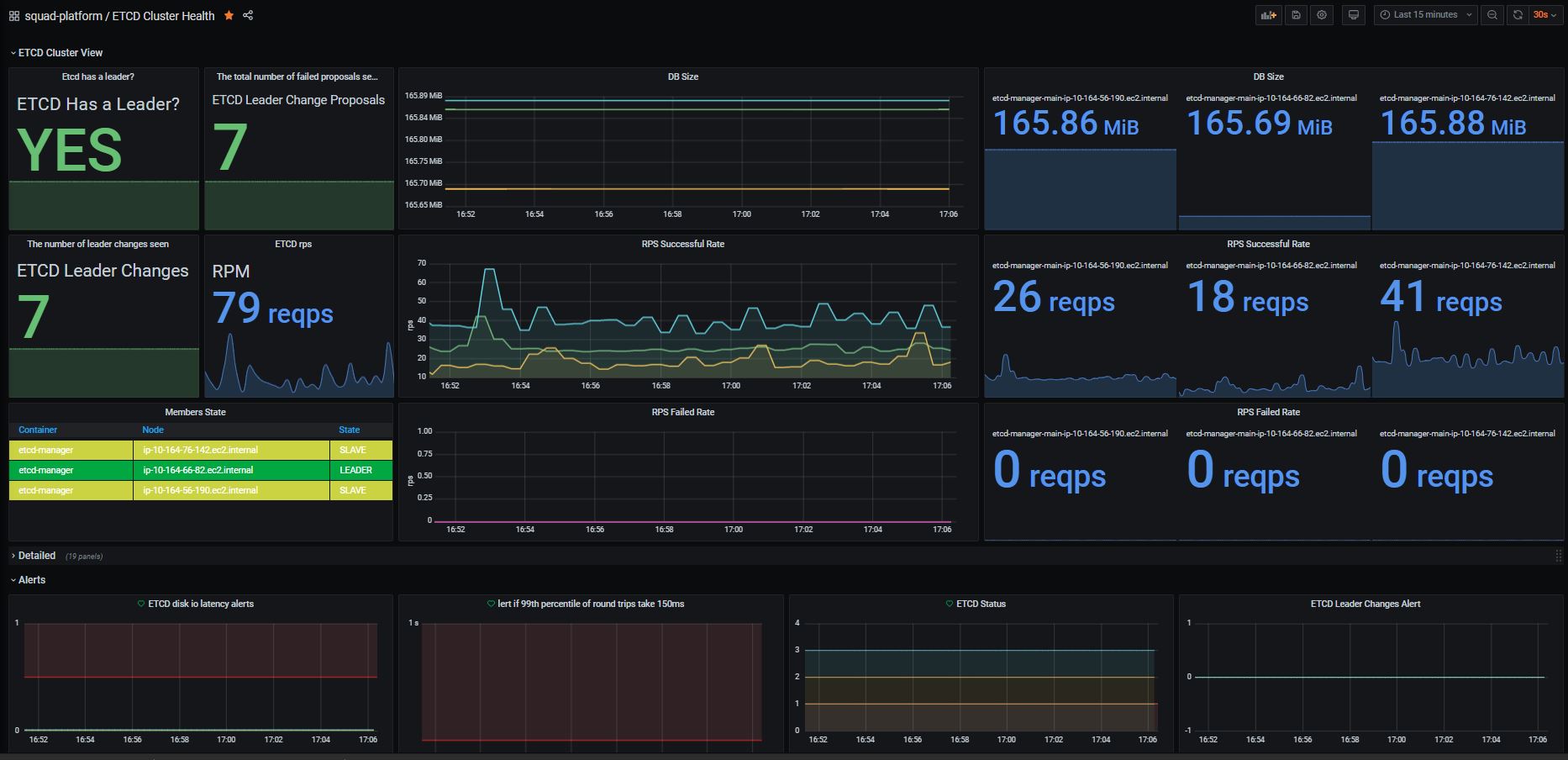
This dashboards will show you all information needed to monitor your ETCD Cluster.
- Cluster Status
- Leader Changes
- Resources Utilization
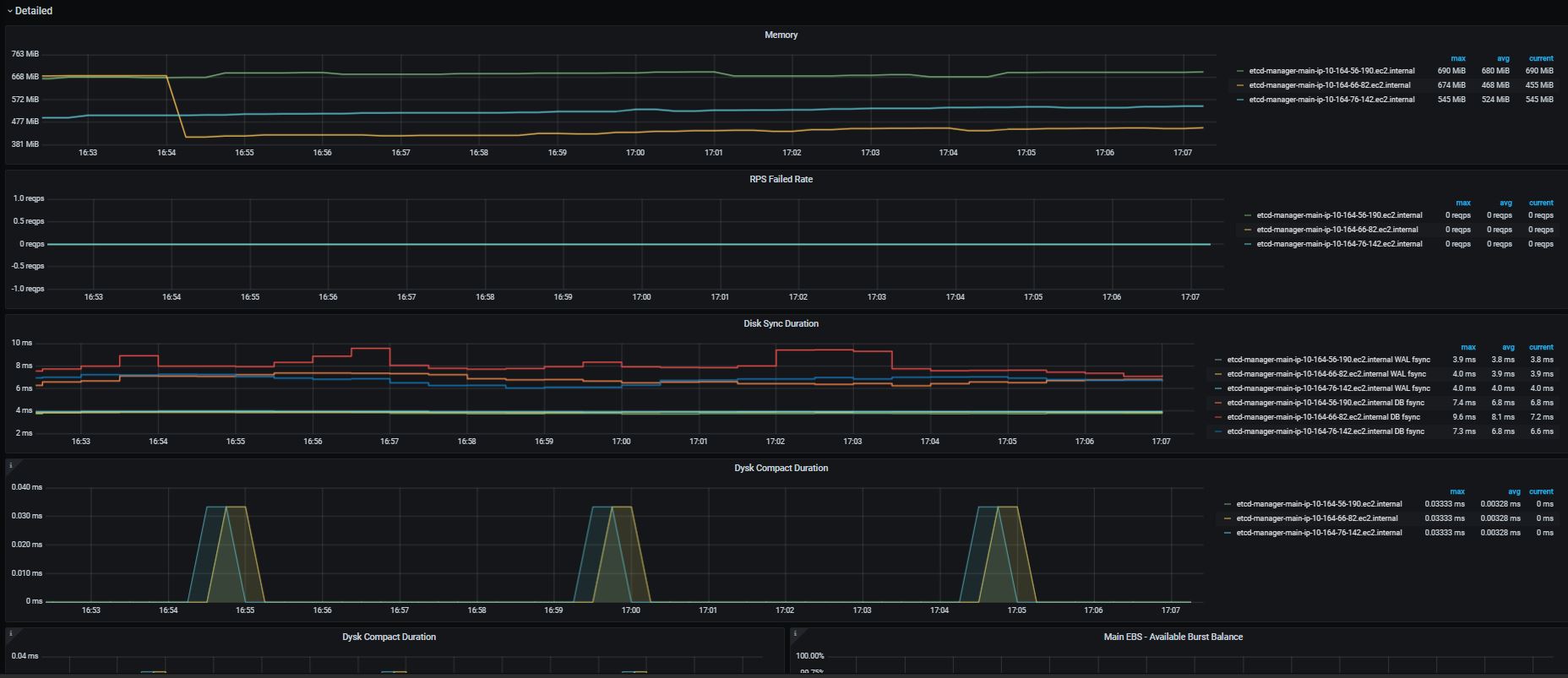
- Detailed informations
- A row of alarms
To use it, you must have:
- Metrics Server Exporter
- Kube State Metrics
- ETCD v3.0.0+
- Kubernetes 1.14.0+
Prometheus ETCD Scrap Config:
- job_name: 'etcd-manager'
kubernetes_sd_configs:
- role: pod
tls_config:
ca_file: /etc/prometheus/etcd-certs/etcd-clients-ca.crt
cert_file: /etc/prometheus/etcd-certs/prometheus-etcd.crt
key_file: /etc/prometheus/etcd-certs/prometheus-etcd.key
insecure_skip_verify: true
scheme: https
metrics_path: '/metrics'
relabel_configs:
- action: keep
regex: ^(etcd-manager-main-.*)$
source_labels:
- __meta_kubernetes_pod_name
- source_labels: [__address__]
action: replace
regex: (.+)
replacement: $1:4001
target_label: __address__
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: node_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod_name
- source_labels: [__meta_kubernetes_pod_container_name]
action: replace
target_label: container_name
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
Export Dashboard✕
Download
Copy to Clipboard
Used Metrics 1111
etcd_server_has_leader
etcd_server_leader_changes_seen_total
etcd_debugging_mvcc_db_total_size_in_bytes
grpc_server_started_total
etcd_server_is_leader
grpc_server_handled_total
etcd_disk_wal_fsync_duration_seconds_bucket
etcd_network_peer_round_trip_time_seconds_bucket
-
up
etcd_debugging_mvcc_db_compaction_total_duration_milliseconds_count
etcd_disk_backend_commit_duration_seconds_bucket